|
You can describe the syntax of a language by describing the
parse trees that are allowed. Anyone creating a parse tree must
follow the rules that you give.
The rules describe what is allowed locally in a tree.
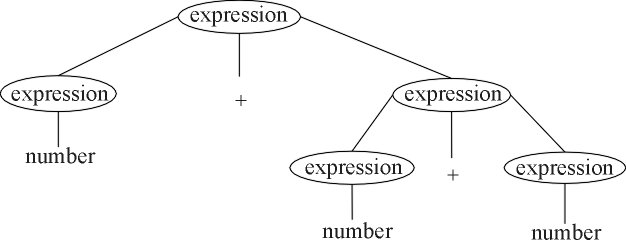
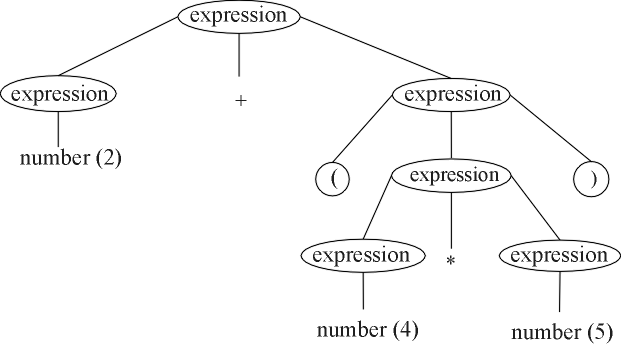
The example tree contains a node labeled expression with
three children, labeled expression, + and expression,
in that order. A rule that indicates this is allowed is
| <expression> ::= <expression> + <expression> |
In rules, labels of nonleaf nodes are usually written in angle brackets.
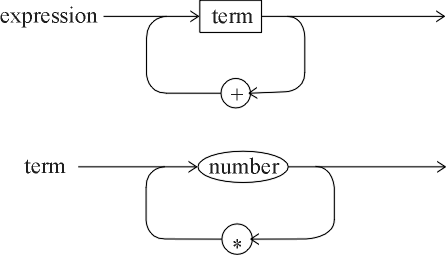
A collection of rules is called a grammar.
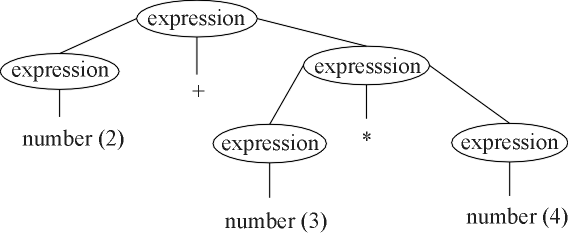
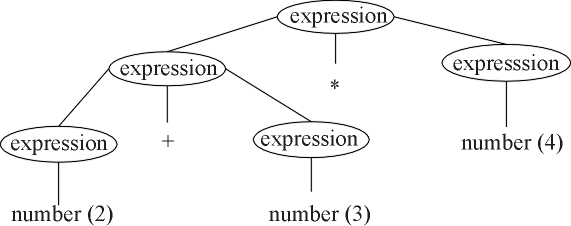
A grammar that allows the parse tree shown above is
| <expression> ::= <expression> + <expression> |
| <expression> ::= <expression> * <expression> |
| <expression> ::= number |
If you have several rules in a row with the same thing on the
left of ::=, you normally write | in each but the first rule. So
the above grammar can be written
| <expression> ::= |
<expression> + <expression> |
| | |
<expression> * <expression> |
| | |
number |
|
Example grammar: statements |
|---|
| <statement> ::= |
<assignment> |
| | |
<if-statement> |
| | |
<while-statement> |
| | |
<procedure-call> |
| |
| <assignment> ::= |
identifier := <expression> |
| |
| <if-statement> ::= |
if <expression> then <statement> |
| | |
if <expression> then <statement> else <statement> |
| | ... |
|
|
|