| Assigned: | Friday, October 4 |
| First version due: | Wednesday, October 23, 11:59pm |
| Second version due: | Friday, November 8, 11:59pm |
Read the entire assignment before you start working on it.
| This is probably the largest program you have ever written. It will take time to write. Start on it early. Do not wait. If you wait until near the deadline to start, you will not finish. |
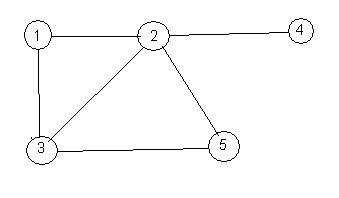
A graph is a collection of vertices connected by a collection of edges. An edge connects exactly two vertices to one another. You can draw a picture of a graph by showing the vertices and the edges connecting them. Here is an example. The vertices are shown as circles with numbers in them and the edges are lines connecting the vertices.
We will only be concerned with connected graphs. A graph is connected if there is a path from every vertex to every other vertex, following edges. For example, in the above graph, there is a path from 3 to 4 that goes (3, 1, 2, 4). There are other paths from 3 to 4 as well.
Two vertices are said to be adjacent if there is an edge that connects them directly to one another. In the graph above, vertices 1 and 2 are adjacent, but 1 and 4 are not adjacent.
A weighted graph is a graph in which each edge has a number attached to it, called the weight of the edge. Here is a picture of a weighted graph.
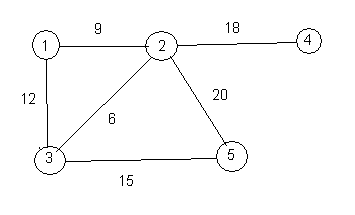
Think of the vertices of a graph as towns and the edges as roads. The weight of an edge is the length of the road. One thing that you might like to know is how to get from one town to another by the shortest possible route. For example, in the weighted graph above, the shortest route from vertex 1 to vertex 5 is to go from 1 to 3 and then from 3 to 5, and the length of that route is 27. You add the weights of the edges that you use.
Write a program that reads information about a weighted graph from the standard input. The input format is described in detail below. After the description of the graph, the input has two vertex numbers, s and t.
Your program should print a description of the graph, followed by the shortest path from s to t and the distance from s to t via that path, on the standard output.
For example, the input might look
like this.
5
1 2 9.0
1 3 12.0
2 4 18.0
2 3 6.0
2 5 20.0
3 5 15.0
0
1 5
That says that there are five vertices. There is an edge from
vertex 1 to vertex 2, with weight 9.0, an edge from vertex 1 to vertex 3
with weight 12.0, etc. The start vertex s
is 1, and the end vertex t is 5.
The output for this input would be as follows.
There are 5 vertices.
The edges are as follows.
(1,3) weight 12.000
(1,2) weight 9.000
(2,5) weight 20.000
(2,3) weight 6.000
(2,4) weight 18.000
(3,5) weight 15.000
The shortest path from 1 to 5 has length 27.000 and is
1 -> 3 -> 5
Please make the last two lines of your output have the form shown above, where the last line shows the path from s to t, with -> between vertices, and the line before that has the form shown. My tester will look for that.
This page describes an algorithm, Dijkstra's algorithm, for solving this problem, and provides additional details on how to implement Dijkstra's algorithm. You are required to use Dijkstra's algorithm, and to follow the guidelines for its implementation. It is not acceptable to rely on a different approach to the problem.
You are required to use sensible terminology in your program. If something is a graph, do not call it an edge. If something is an edge, do not call it a vertex. Make variable and type names sensible. Keep functions short and simple.
As always, every function must have a clear contract stating what it does, not how it works. All code must be well indented and readable.
The input starts with a line that tells how many vertices the graph has. If there are five vertices, then those vertices have numbers 1, 2, 3, 4 and 5. In general, if there are n vertices, then they are numbered 1, ..., n.
Following the first line are
the edges, one per line. Each edge line has two integers and one
real number on it.
Line
2 4 5.4
indicates that there is an edge between vertices 2 and 4,
and that its weight is 5.4. The end of the list of edges is signaled
by a line that contains just a 0. After that are the numbers
for vertices s and t. An input describing graph
with start vertex 2 and end vertex 4 might look like this.
5
1 2 9.0
1 3 12.0
2 4 18.0
2 3 6.0
2 5 20.0
3 5 15.0
0
2 4
Important note. The first number in the input is the number of vertices, not the number of edges. Do not use that number to determine how many remaining lines need to be read. Just keep reading edges until you read a 0.
There is an algorithm called Dijkstra's algorithm that you can use to find shortest paths. This section describes how that algorithm works.
You will need to store some information for each vertex in the graph. Create an array holding a structure for each vertex. (So it will be an array of structures.) Store the following information for each vertex.
Each vertex has a status value (one of Done, Pending or Peripheral). A vertex with status Done is called a done vertex, a vertex with status Pending is called a pending vertex, and a vertex with status Peripheral is called a peripheral vertex.
Each vertex has a current distance from the start vertex. For convenience I will write dist(v) in this section for the current distance value stored for vertex v. (Do not presume that this is C++ notation.. You might write g.info[v].distance in your program to get the distance stored with vertex v in graph g. You will rarely find that an algorithm is described in exactly the terms that you will use for a particular implementation of that algorithm in a particular programming language.)
The algorithm builds up the shortest path backwards, indicating, for each vertex v, how to get from v back to the start. Each vertex has a current next-vertex, which is the next vertex to go to on the way back to the start. For convenience I will write next(v) for the current next-vertex stored with vertex v. Again, this is not intended to be the way you will write this in your C++ program. You might write g.info[v].next instead of next(v).
Each vertex has a linked list of edge descriptions, telling the vertices that are adjacent to this vertex, and the weight of the edge that connects them. So each cell in the linked list holds (1) another vertex number and (2) a weight. (This list is called the adjacency list of this vertex; it is described in more detail in the design section below.)
A done vertex v has been finished, and dist(v) is the correct shortest distance from v back to the start, s. The shortest path from v to s begins by going to next(v). It continues to vertex next(next(v)), then to next(next(next(v))), etc. until it reaches s.
A pending vertex v is adjacent to at least one done vertex, but is not done. When v is pending, dist(v) is the shortest distance from v to s, provided there is a restriction that the path taken from v to s must begin by going from v to a done vertex. (There might be shorter paths that begin with an edge from v to a vertex that is not yet done.) When v is pending, the currently best known way to get from v to s is to start by going to next(v), and continuing by the shortest path to s from there.
A peripheral vertex is one that is neither done nor pending. Its current distance and next-vertex values are meaningless. There is no edge between any done vertex and any peripheral vertex.
The algorithm begins by marking the start vertex s as done and setting dist(s) to 0. Each vertex v that is adjacent to s is marked pending, with dist(v) set to the weight of the edge between v and s, and next(v) set to s. All other vertices are marked peripheral.
After initializing, the algorithm repeatedly performs phases, until vertex t (the target vertex) is done, or there are no more pending vertices. Each phase works as follows. It is assumed that there is at least one pending vertex.
When the algorithm is finished, you will be able to follow a path
from t back to s by following the chain of next vertices.
t -----> next(t) -------> next(next(t)) ----> ... -----> s
Print that chain out backwards, so that it goes from s
to t instead of from t to s.
The easiest way to do that is
to use recursion. To print a path backwards, starting at vertex u,
print the path starting at next(u) backwards, then print u.
Of course, in the special case where u is the start vertex
s, just print s. Remember to put -> between
vertex numbers.
Create a module, graph.cpp, that is responsible for managing graphs, for Dijkstra's algorithm, and for the main program. Initially, this will be the only module in the program.
Create a structure type, Vertex, that contains information about one vertex. It should contain a status, a next-vertex value, a current-distance value and a pointer to an adjacency list for this vertex, as described above. Keep in mind that a Vertex structure stores information about one vertex, including a linked list of other vertices to which that one vertex is connected.
Create a structure type, Graph,
that contains information about an entire
graph. It should hold (1) the number of vertices, (2) a pointer to
an array of Vertex structures, giving information about every vertex in the graph.
Here is a suggestion for the Graph type definition.
struct Graph
{
int numVertices;
Vertex* info;
};
For example, the graph shown above would be represented as follows. The upper number in each list cell is a vertex number, and the lower number is the edge weight. (Remember that the weight is, in general, a real number.) The ... parts of the array are the other information (status, distance, next).
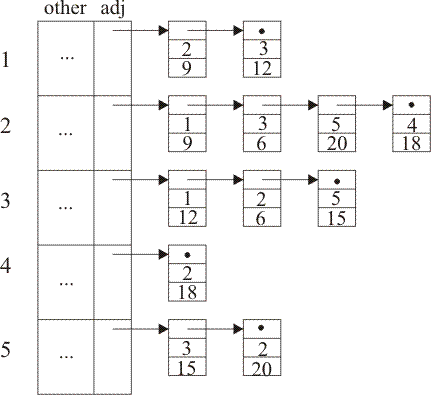
Provide functions to do the following tasks.
Read a graph, in the format described above. Build up the adjacency lists as you read the graph. When you read an edge from u to v, put it into both the adjacency list of u and the adjacency list of v. That is, indicate that u is adjacent to v and v is adjacent to u.
Print a graph. To print a graph, show the number of vertices and all of the edges, as shown above in the example. You only want to show each edge once, even though it is in two adjacency lists. To do that, scan each adjacency list, but only print an edge when it goes to a higher numbered vertex, to avoid printing it twice. You will have two nested loops, an outer one that goes through the array of Vertex structures, and an inner one that goes through the adjacency list of a particular vertex.
Find a pending vertex with the smallest current distance. This is used in step 1 of a phase of Dijkstra's algorithm.
Perform the update step (step 3) of a phase of Dijkstra's algorithm. This function will need to be passed the graph as a parameter, as well as the vertex u that was found in step 1. Pass the graph by reference, so that you do not make a copy of it.
Perform a complete
phase of Dijkstra's algorithm.
This function will need to be passed the graph that it works on.
Again, be sure to pass the graph by reference to avoid copying it.
It might have a heading like the following.
void DoOnePhase(Graph& g)
Run Dijkstra's algorithm. This needs to do the initialization and then it needs to perform phases until the end vertex, t, is done.
Print the path from s to t that was found by Dijkstra's algorithm. This function will need to have s, t and the graph as parameters.
The main program. This should, by calling functions, (1) read in the graph, (2) print the graph, (3) run Dijkstra's algorithm and (4) print out the shortest path that was requested.
You can use an enumerated type to create the type of status values. The following line defines a new type StatusType, and creates constants Done, Pending and Peripheral, all of type StatusType.
enum StatusType {Done, Pending, Peripheral};
In general, an enumerated type is a type with a fixed, finite set of members
that are listed in the type definition. Line
enum T {a,b,c,d};
creates a new type T that has four members, called a, b, c and d.
The find step (step 1) of Dijkstra's algorithm needs to find a pending vertex that has the smallest possible distance. One way to do that is to look at every vertex. But that can be expensive when there are many vertices, and, for large graphs, that is the most expensive part of the algorithm. An alternative is to put the pending vertices into a specialized data structure that is good for locating smallest things in a group of things. Such a data structure is called a priority queue.
A priority queue holds a collection of items, each having a priority attached to it. (So the members of a priority queue are structures.) For our purposes, each item is an integer, and each priority is a real number. When a priority queue is created, it is empty. That is, it has no items in it.
The following operations are available for a priority queue q.
Insert item v (an integer) with priority p into priority queue q. Parameter q is a reference parameter, but v and p are value parameters.
Remove the item (an integer) from priority queue q that has the smallest priority, and set variable v to that item, and p to its priority. The parameters of remove must be reference parameters. Logically, v and p are out-parameters, since they represent information being sent from the remove function to its caller, not the other way around. If the queue is empty, remove should set v = 0 and p = 0.
Replace the priority of value v in priority queue q by p. This function assumes that v is already in the priority queue.
Return true if q is empty.
You can use a priority queue to keep track of the pending vertices by doing the following.
When a vertex is marked pending for the first time, insert it into the priority queue, with its current distance being its priority.
When the distance of a pending vertex is updated, also update its priority in the priority queue.
To find the pending vertex with the smallest distance, use the remove function to get it from the priority queue.
You will find that you need to add a priority queue as a parameter to some functions. Pass it by reference. Also be sure to update the documentation so that the contract explains the purpose of the priority queue.
For this program, your priority queues use items that are integers (vertex numbers) and priorities that are real numbers. But you can imagine other kinds of priority queues. For example, some other program might need a priority queue whose items are real numbers and whose priorities are integers. Yet anothe program might need one whose items are Widgets and whose priorities are integers.
So you might want to modify the types of items and priorities.
To do that, say what the item and priority types are in just
one place. Use type definitions
typedef int PQItemType;
typedef double PQPriorityType;
to define type PQItemType to be int and PQPriorityType to be double.
Write the entire implementation of priority queues using PQItemType for the type of an item and PQPriorityType for the type of a priority. Do not presume that PQItemType is int or that PQPriorityType is double, since that might be changed for another version of priority queues. You should only need to change the definitions of PQItemType and PQPriorityType to change those types.
You will implement priority queues by creating a module pqueue.cpp that holds the function definitions and pqueue.h that describes what pqueue.cpp provides.
There are some clever and very efficient ways of implementing priority queues, and that is part of the reason for using them. However, we will not try to use any of them here. Instead, we will adopt a simple approach that is less efficient. But later on you could replace this simple implementation with a more efficient one. It is critical that your implementation of graph.cpp does not use any details of the priority queue implementation, so that pqueue.cpp and pqueue.h can be replaced later by a better implementation without making any changes to graph.cpp.
Represent a priority queue as a linked list, storing an item (an integer) and its priority (a real number) in each list cell. Keep the list in ascending (or, really, nondescending) order of priority. So the item with the smallest priority is at the front of the list.
Create two structure types, one for the cells of the linked list, and one for the PriorityQueue type. Here are some suggestions for them.
struct PQCell
{
PQItemType item;
PQPriorityType priority;
PQCell* next;
PQCell(PQItemType i, PQPriorityType p)
{
item = i;
priority = p;
}
};
struct PriorityQueue
{
PQCell* ptr;
PriorityQueue()
{
ptr = NULL;
}
};
The remove function is very easy, since the item to remove is at the front of the linked list. Just remove it, then delete the list cell.
You will find the insert function very easy to implement if you use recursion. The new item either belongs at the beginning of the list or it doesn't. If it belongs at the beginning of the list, just create a new list cell and install it at the beginning, by inserting it as the new first cell in the list. If the new item does not belong at the beginning, a recursive call to insert will finish the job.
But you have to be careful with recursion. You cannot do recursion
on something of type PriorityQueue, since a PriorityQueue does not have
a recursive structure. It only contains a pointer to a PQCell. But a PQCell
does have a recursive structure because it contains another pointer to a
PQCell inside it. So, to implement insert, write two functions, one that
works on PQCells and is recursive, and one that works on a PriorityQueue.
void insertCell(PQCell*& cell, PQItemType v, PQPriorityType priority)
{
...
}
void insert(PriorityQueue& q, PQItemType v, PQPriorityType priority)
{
insertCell(q.ptr, v, priority);
}
Notice that the insert function just delegates the job to
the recursive function insertCell.
You will find it convenient to write an auxiliary function to
remove a given item from the
list. For example, it might have the following contract and heading.
// removeItem(q,v) removes item v from priority queue q.
void removeItem(PriorityQueue& q, PQItemType v)
This function is not to be used by any other module, since it is
not an official part of the priority queue implementation. (A more
efficient implementation of priority queues might not be able to handle
removal of an arbitrary member, so other modules should not
presume that such a function is available.)
Again, recursion makes this very easy. Either v is in
the first list cell or it is not. Decide what to do in each case.
To do an update, just remove the item and re-insert it with a new priority. Do not try to be excessively efficient. Remember that, if you find that you need efficiency in this module, you will want to throw away this entire way of implementing it, and use a more efficient data structure, so don't waste your time trying to make this one really efficient. (But don't be extravagant either, and do things in wildly inefficient ways. If a priority queue in your implementation has n things in it, then the cost of doing an operation on it be no worse than proportional to n, not to n2. More efficient algorithms will drop the time to log2(n).)
Create files pqueue.h and pqueue.cpp that together define the priority queue module. Only describe in pqueue.h what you need to for other modules to be able to use priority queues. Do not even mention removeItem or insertCell in pqueue.h. They are only for use inside pqueue.cpp.
The final version of your program should contain files graph.cpp, pqueue.cpp and pqueue.h. It should solve the shortest distance problem as indicated above, and it should use a priority queue in step 1 of a phase of Dijkstra's algorithm.
Here is a suggested refinement plan for implementing this program.
Create file graph.cpp. Define the structure types. Write a contract and heading for each function. Make sure the contract is clear and precise, not just a hint. Make sure that each contract says what each parameter is for, and how it affects what the function does. Refer to parameters by name. For example, say "graph g", not "the graph".
Implement the function that reads a graph, and the function that prints a graph. Test them, by reading and printing a graph. The graph-reading function should store the edge information in the adjacency lists. Do not try to store it in some other way.
Implement Dijsktra's algorithm, using the simple implementation of the find step that does not use a priority queue. Test it. Just print the information in the array in a raw form to see that it is right rather than trying to print the path in the final form. Your main function should be growing in the direction of the final version.
Implement the function that prints the path. Test it. Your main program should have reached its final form now. Your program should do what it is supposed to do.
Create a set of tests. Modify your Makefile to perform all of the tests automatically. Your mindset in making the tests should be to try to find mistakes. Look at the answers. Do you think they are right?
Create a new directory for the second version of the program. Make a copy of your implementation of Dijkstra's algorithm, putting the copy in the new directory. Copy over your makefile. Do not destroy your working program.. Keep the old version around. The remaining work should be done in the new directory.
Implement the insert and remove functions in the
priority queue module. Add a function that prints the contents
of the list. Create a new main function, in a different (test) module
such as testq.cpp, that is only used to test the priority queue module.
Do not modify graph.cpp yet. Include pqueue.h into testq.cpp. Compile
testq.cpp and pqueue.cpp together. (That means do something like the
following to create executable program qtest.
g++ -Wall -o qtest pqueue.cpp testq.cpp
The compiler puts the two modules together.)
You will probably find it useful to add debug prints.
Implement the remaining priority queue functions. Test them.
Modify your implementation of Dijkstra's algorithm to use a priority queue. Only put pending vertices in the priority queue. You will need to modify the functions that perform the find and update steps. The find step removes a vertex from the priority queue. The update step performs insertions and updates in the priority queue, to keep the information about pending vertices stored there correct.
Run your tests on the new algorithm. Do they work? You should get the same answers as you got from the first version. You can add new tests if you want to. Since you still have the old version, you can run both algorithms and compare the answers.
After you are confident that your program works, submit it.
Here are some things to do and mistakes to avoid, with a range of points that you might lose (out of 100) for each one.
Write your name, the course and the assignment number in a comment at the top of the program, along with the tab stop distance. (up to 2 points)
Failure to compile (100 points). Your program is expected to compile. A program that has fatal compile errors will receive a grade of 0.
Compiler warnings (up to 5 points). Your program should not have any compiler warnings.
Failure to follow the design (up to 100 points). The design requires you two write certain functions. It also says what those functions must do. It is not acceptable to substitute a different design.
The design does not call for global variables. Do not use global variables, with the exception of a variable for turning tracing on and off. Other than that variable, using even one global variable means that you are not following the design, and can lead to a very high loss of points.
Partial program. If only part of the program is written, you will receive some credit, depending on how much is written, and how well that part is written. Do not count on a great deal of credit for a partial program that cannot be run, or that only reads and echoes the input.
Incorrect results (up to 30 points). The program should produce correct results.
Memory faults (up to 30 points). If your program encounters a memory fault then it does not do what it is supposed to do. Ensure that you do not use an uninitialized or dangling pointer. Do not use an index that is outside the bounds of an array.
Incorrect modules (up to 10 points). Break the program into modules as described in the design. If you turn in a partial version that does not use or implement priority queues then there is no need to have the priority queue module. But see the next item.
Program does not use priority queues (up to 25 points). This programming assignment is partly intended to be an exercise in creating and using an abstract data type. If you turn in a version that does not employ the priority queue abstract data type, you will lose substantial points.
Violate the abstraction of the PriorityQueue abstract data type (up to 20 points). In graph.cpp you can use type PriorityQueue, and you can use the insert, remove, update and isEmpty functions, and nothing else. Module graph.cpp must not use type PQCell for any reason. It must not use any variable of the PriorityQueue structure for any reason. For example, if q has type PriorityQueue and graph.cpp mentions q.ptr, then you have violated the abstraction, and can count on losing points.
Incorrect use of PQItemType and PQPriorityType (up to 5 points). Your priority queue module (pqueue.h and pqueue.cpp) should be written so that changing the types of items involves changing only the definition of type PQItemType, and changing the priority type requires only changing the definition of PQPriorityType.
Types PQItemType and PQPriorityType have just one purpose: to make it easy to modify the priority queue module. So they should not occur at all in any other module. If your graph.cpp module mentions PQItemType or PQPriorityType, it is wrong. In graph,cpp, you know that the priorities are real numbers and the items are integers.
Private functions advertised in header file (up to 3 points). File pqueue.h should say as little as possible about things that should only be used in pqueue.cpp. It should contain a prototype for insert, since that is something that other modules need to use. But it should not contain a prototype for functions, such as insertCell and removeItem, that are only intended to be used in pqueue.cpp to help implement the other functions.
Poor or missing contracts (up to 15 points). Every function must have a clear and precise contract. A contract tells what a function does, not how it works. A contract tells precisely how every one of its parameters affects what the function does, and refers to parameters by name.
Functions do not do what they are supposed to do, or return incorrect results according to their contracts (up to 7 points per function).
Crippled functions (up to 8 points). A crippled function is one that does not really do its job, but requires its caller to do part of the job.
Memory leaks (up to 5 points). When you remove something from a priority queue, be sure to delete memory that becomes inacessible. Ensure that you do not have a memory leak when you read in a graph.
Do not worry about deleting everything just before your program finishes. That is done automatically anyway.
Poor indentation (up to 10 points). You are expected to indent your function definitions correctly. Minor problems will not lose much, but seriously bad indentation can lose 10 points.
Failure to explain tabs (2 points). Be sure that you either do not use tabs in your program or that you tell where your tab stops are at the top of the program. Different editors are set up with different tab stops. For example, write
// tab stops: every 4 charactersIf you do not know where the tab stops are, do not use tabs.
Wrong status values (up to 3 points). The design requires you to use enumerated type StatusType for status values. If you use some other type of status value, you will lose points.
Excessively complicated algorithms (up to 5 points per algorithm). If you need to look at every vertex that is adjacent to vertex u, the correct way to do it is simply to loop through the adjacency list of u, since that list contains exactly the vertices that you want. A wrong approach that is both excessively complicated and very inefficient is to try every vertex v, from 1 to n, and to ask whether each v is in u's adjacency list.
Poor or misleading type, function or variable names (up to 5 points). Uses sensible names. You can use short names (such as s or t) in short functions where it is clear what they mean and using short names makes the program more readable. But never use a name that suggests something that only confuses a reader. Also, do not use a variable name such as number. That provides no information about what the variable really represents.
Excessive inefficiency (up to 5 points). Do not do simple things in outrageously slow ways. If you are using the priority queue, you must take advantage of the potential efficiency that it offers you. You must not continue to look at every vertex in order to do one phase. (The purpose of the priority queue is to avoid looking at every vertex.)
Long lines, margin comments (up to 5 points). Avoid long lines. As a rule of thumb, keep lines at most 80 characters long. Avoid margin comments (comments written in the right margin telling what the code to the left of them does). Those comments rarely say anything useful, and they make lines long and clutter the program. If you need to write a comment inside a function, write a paragraph comment telling what the next paragraph of code does.
Packing functions together (up to 1 point). Put a blank line between function definitions. There is no need to pack them together. That makes the program more readable.
But also do not put huge blank sections in your program consisting of several blank lines in a row. A long space is two blank lines. Longer than that is excessive.
system("pause") (up to 5 points). Some programmers write system("pause") at the end of main to compensate for a flaw in the design of a Windows development environment. Since that is a nonstandard thing, I must edit your program to get rid of it before I can test your program. I should not have to fix your program for any reason.
To turn in this program, log into one of the Linix computers in the lab. (You can log in remotely.) Ensure that your files are there. Change to the directory that contains those files. Then issue one of the following commands.
~abrahamsonk/3300/bin/submit 3a graph.cpp pqueue.cpp pqueue.h
~abrahamsonk/3300/bin/submit 3b graph.cpp pqueue.cpp pqueue.h