| Assigned: | Thursday, April 4 |
| Due: | Monday, April 22, 11:59pm |
| Points: | 800 |
This assignment has you use trees. It also does less hand-holding than previous assignments. It is the largest assignment that you are assigned, and gives you experience in implementing a multi-module program.
It is crucial to get started early. This program will take a lot of time to write. You will need to write approximately 24 functions. Make a plan for getting this assignment done early without trying to do too much in one day.
Use the methods that we have studied in this course. Do not cut corners. Do not revert to novice methods! They will not speed you up. They will slow you down.
Read the entire assignment before you start on it.
When faced with a large assignment near the end of a term, many students turn to plagiarism, especially if they have waited too long to start on the assignment.
Do not fall into that trap and submit a plagiarized assignment. Doing so will cost you points. Keep in mind that you must get an overall score of 50% or better on the programming assignments in order to pass this course, and that a plagiarized assignment gets a negative score. Submitting plagiarized or partially plagiarized work can cause you to fail this course.
Data compression is concerned with economical ways to encode information for storing files using limited disk space or for transfering files over a network. Data compression is critical for transmitting videos over the internet and storing high-definition videos.
Sophisticated data compression algorithms for text files take into account sequences of characters that occur often, so that they can encode those sequences in an efficient way. For example, if the word Rumpelstiltskin occurs often, then there will be a short code for that word.
A much simpler kind of data compression for text files works on individual characters, without paying attention to how characters are grouped. This assignment has to do with that simple form of data compression, using an algorithm called Huffman coding.
A file is a sequence of bits. Codes such as Ascii and Unicode use a fixed number of bits to encode each character. For example, in the 8-bit Ascii code, the letters 'a', 'b' and 'c' have the following encodings.
| 'a' | 01100001 | |
| 'b' | 01100010 | |
| 'c' | 01100011 |
In the 16 bit Unicode standard, the codes for 'a', 'b' and 'c' are as follows.
| 'a' | 0000000001100001 | |
| 'b' | 0000000001100010 | |
| 'c' | 0000000001100011 |
Some characters are used more than others. In fact, you very likely don't use some characters at all (especially if you are using Unicode!). For an economical encoding, instead of using the same number of bits for every character, it would be better to use shorter codes for characters that occur more frequently, and to have no code at all for a character that is not used.
For example, suppose that a document contains only the letters a, b and c, and suppose that the letter b occurs far more often than either a or c. An alternative character encoding is as follows.
| 'a' | 10 | |
| 'b' | 0 | |
| 'c' | 11 |
That code has the property that no character code is a prefix of any other character code. Using that kind of character code (called a prefix code) allows you to break apart a string of bits into the characters that it encodes without having any character boundaries stored. For example, string of bits "01001110" encodes "babca". To decode a string, you repeatedly remove a prefix that encodes a character. Since no code is a prefix of any other code, there is only one way to select the next character.
There is an algorithm that is due to Huffman for finding efficient prefix codes. The input to the algorithm is a table of characters with their frequencies.
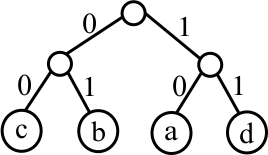
A tree is used to define a prefix code. Each node of the tree is either a leaf or a nonleaf. Each leaf contains a character. Each nonleaf has two children, the left child and the right child. We think of the left child as the '0' child and the right child as the '1' child. An example is the following tree.
You find the code for a character by following the path from the root of the tree to that character, writing down the 0's and 1's that you see along the path. For example, in the tree above, the code for 'b' is 01 and the code for 'a' is 10. What is the code for 'c'? A different code is given by the following tree.
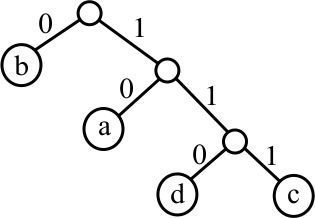
where 'b' has code 0, 'a' has code 10, 'd' has code 110 and 'c' has code 111.
A tree can be thought of as a composite character. A tree with leaves a and c stands for the combination of a and c. A character by itself is thought of as a tree that has just one leaf.
The algorithm to create the tree starts by making each character
into a tree that is just a leaf holding that character. Each tree has
a frequency, which is the number of occurrences of the character
in the file.
For example, if the frequency counts are
a 500
b 230
c 300
d 250
e 700
(so 'a' occurs 500 times, etc.)
then the algorithm creates five leaves, one (holding a)
with frequency of 500,
one (holding b) with a frequency of 230, etc.
(Note. A frequency is associated with an entire tree, not with each node of a tree. Initially, each tree has just one node, but as the algorithm runs the trees will grow. You still have just one frequency per tree.)
Now the algorithm repeatedly performs the following steps, as long as there are still at least two trees left in the collection of trees.
Remove the two trees that have the lowest frequencies from the collection of trees. Suppose that they are trees S and T. Suppose that tree S has frequency FS and tree T has frequency FT.
Build a tree that looks as follows.
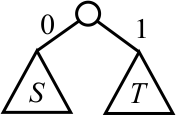
Say that this tree has frequency FS + FT, the sum of the frequencies of S and T.
Add the new tree, with its new frequency, to the collection of trees.
The number of trees decreases each time because you remove two trees and put back just one tree. When there is only one tree left, the algorithm is done. That tree is the result.
It is a little awkward to draw pictures of the trees, so a notation for describing trees is useful. A leaf is shown as the character at that leaf. A nonleaf is shown as the two subtrees, surrounded by parenthese and separated by a comma. For example, tree
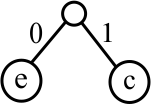
is written (e,c). Tree
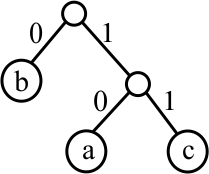
is written (b,(a,c)). Tree
is written ((c,b),(a,d)). We use this notation to demonstrate the algorithm.
Suppose there are five letters, a, b, c d and e. After counting the characters in a document, suppose that you get the following counts.
| a | 500 |
| b | 230 |
| c | 300 |
| d | 250 |
| e | 700 |
The initial collection of trees (all leaves) with their frequencies is as follows.
| b | 230 |
| d | 250 |
| c | 300 |
| a | 500 |
| e | 700 |
Removing the two with the smallest frequencies and combining them yields a tree with frequency 480. It is inserted into the collection, yielding the following.
| c | 300 |
| (b,d) | 480 |
| a | 500 |
| e | 700 |
The next step combines c with (b,d), yielding tree (c,(b,d)), with a frequency of 300 + 480 = 780. The collection of trees and frequencies is now
| a | 500 |
| e | 700 |
| (c,(b,d)) | 780 |
Now combine a and e, yielding
| (c,(b,d)) | 780 |
| (a,e) | 1200 |
The last step combines the last two trees, yielding
| ((c,(b,d)),(a,e)) | 1980 |
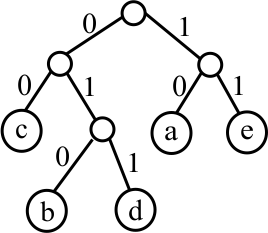
The final tree is ((c,(b,d)),(a,e)), which is the following tree.
For this assignment you will write two applications. Files huffman.cpp and unhuffman.cpp will each contain a main function and will be run separately.
The first application, called huffman, gets two file names, which I will refer to as A and B, from the command line, where A is argv[argc − 2] and B is argv[argc − 1]. It should do the following.
Count how many occurrences of each character are in file A.
If requested, show the character frequencies on the standard output, showing only characters that occur at least once.
Construct a Huffman tree T for those characters.
If requested, show the tree on the standard output, using the notation described above.
Construct a Huffman code from the Huffman tree (ignoring characters that do not occur at all).
If requested, show the Huffman code on the standard output.
Open file B and write a binary description of the Huffman tree T into B.
Reread file A and, using the constructed Huffman code, write an encoded version of file A into file B (after the tree). Close the files.
For example, command
./huffman data.txt data.cmp
reads file data.txt and writes a compressed version into
a file called data.cmp.
The second application, called unhuffman,
will also be given two file names,
A and B, on the command line.
It reads file A, which
must be a file that was written by your huffman application, and
it writes file B, which must be the decoded version
of A.
For example, command
./unhuffman data.cmp newdata.txt
reads data.cmp and writes newdata.txt.
The decoded file should look identical to
the file that you encoded.
The compressed file contains a binary description of a Huffman tree followed by a sequence of character codes. Your unhuffman algorithm should start by reading and building the tree. If requested, unhuffman should show the tree that it gets from file A.
Then it uses the tree to get character codes from file A and write the decoded characters into file B.
Assume that the original file has at least two different characters in it. Your program is not required to work correctly on a file that has no characters or only one character, possibly repeated.
As always, you are required to follow the design that is explained below.
In this assignment, you are allowed to add additional functions. You can also add parameters to required functions that are not mentioned in the design, provided that the roles of those parameters are clearly documented.
You are required to provide for tracing, as outlined above (at if requested lines). If the command line contains -t, then tracing is turned on. Otherwise, tracing is turned off.
In Linux, it is conventional for options such as -t
to occur before file names on commands. Command
./huffman -t data.txt data.cmp
requests compression with tracing.
Your huffman/unhuffman programs are required to contain tracing as follows, if tracing is turned on.
The huffman program should show the character frequencies,
the Huffman tree that it produces, and the Huffman code that
it gets.
For example, the output of huffman
with tracing turned on might look as follows.
The character frequencies are:
a 500
b 230
c 300
d 250
e 700
The Huffman tree is: ((c,(b,d)),(a,e))
A Huffman code is as follows.
a 10
b 010
c 00
d 011
e 11
The unhuffman program should show the tree that it reads from the binary file. If it is not identical to the tree that was produced by huffman, there is trouble, so check that (by inspecting it).
| Development plan | |||
|---|---|---|---|
|
1. Create a directory to hold assignment 8.
Get file Makefile and put it in that directory. Look at Makefile to see what the targets are and what they do. | |||
|
2. Create files trace.cpp and trace.h
Add a function to trace.cpp that sets the trace level according to whether the command line contains -t. Put a prototype for that function in trace.h. | |||
|
3.Create file huffman.cpp, the source file for the compression program.
Copy the template into huffman.cpp. Make huffman.cpp #include "trace.h". In huffman.cpp, modify 'main' so that it that sets the trace-level. Also make 'main' show the name of the file that it will compress and the name of the file that it will write. Test what you have in huffman.cpp. Does it set the trace level correctly? Does it get the correct file names? | |||
|
4. Write a function in huffman.cpp to get the character frequencies.
Assume the characters in the file are 8-bits (one byte), so there are 256 possible characters. See reading files using the cstdio library. The parameters of this function should be the name of the file to read and an array of 256 integers to fill with character frequencies. If the array is called freq, then freq[i] will hold the frequency of character i after this function is finished. This function will need to start by storing 0 at each index in freq. This function needs to open and close a file. Make it return true if the file was opened successfully and false if not. Do not put two loops in this function. Create one or two helper functions. Create an array of 256 integers in 'main' to store the frequency counts, one for each possible character that can be stored in one byte. Make 'main' call the frequency counter. If the frequency counter could not open the file, then 'main' must write a meaningful message to the user that includes the name of the file that could not be opened and the program must stop.
| |||
|
In trace.cpp, write a function that takes an unsigned character c as a parameter and prints c's description. The description of 'a' is just a. But the description of '\n' (the newline character) should be \n, or some other desriptive name, such as newline. Use descriptive names for the tab ('\t') and space characters as well. For an unprintable character whose integer code is m, use description \m. For example, the character with code 127 will have description "\127". To check whether a character is printable, #include <cctype>. Then isprint(c) is true if character c is printable and is not a white-space character. Pass isprint a nonnegative integer code or an unsigned character, since it uses the character as an index in an array. | |||
|
6. Add a function to trace the frequency counts.
In trace.cpp, write a function that takes appropriate parameters and, if tracing is turned on, shows the frequencies of all characters that occur at least once in a clear and readable format. Write character descriptions, not raw characters, using the function that you wrote in step 5. In huffman.cpp, make 'main' trace the frequency counts (if tracing is turned on). Test your program. Does it seem to work? | |||
|
7. Create file tree.h to hold the following type definitions.
#ifndef TREE_H
#define TREE_H
// Each node is either a leaf or a nonleaf. Type
// NodeKind has just two values: leaf and nonleaf.
enum NodeKind {leaf, nonleaf};
// An object of type Node is node in a Huffman tree.
// The variables are as follows.
//
// kind tells whether the node is a leaf.
//
// ch is the character stored in a leaf.
// It should only be used for leaves.
//
// left
// right These are the left and right subtrees.
// They should only be used for nonleaves.
struct Node
{
NodeKind kind;
char ch;
Node* left;
Node* right;
// Create a leaf holding character c.
Node(char c)
{
kind = leaf;
ch = c;
}
// Create a nonleaf with left subtree L
// and right subtree R.
Node(Node* L, Node *R)
{
kind = nonleaf;
left = L;
right = R;
}
};
typedef Node* Tree;
#endif
You will lose points if you use the ch field of a nonleaf or the left or right fields of a leaf. You should include tree.h in any file that needs to use the NodeKind, Node or Tree types. | |||
|
8. Write a function that prints a description of a tree.
Add a function to trace.cpp that prints a tree to the standard output using the notation described above. To show a leaf in the tree, show the character's description, not the raw character. | |||
|
9. Write a function that builds a Huffman tree.
In huffman.cpp, write a function that takes the array of character frequencies and returns a huffman tree based on the frequencies. The huffman tree should have type Tree. For Assignment 6 you implemented the priority queue abstract data type. Copy pqueue.h and pqueue.cpp into the directory for assignment 8 and modify pqueue.h by defining #include "tree.h" typedef Tree ItemType; typedef int PriorityType;That is, an item is a tree and a priority is an integer. To build the huffman tree, create a priority queue. Insert a leaf into the priority queue for each character whose frequency is not 0, with its frequency as its priority. Notice that
Tree t = new Node('a');
creates a leaf holding character 'a'.
Now repeatedly remove two trees r and s from the priority queue. Combine them into a single tree by making them the left and right subtrees of a new node. Statement Tree t = new Node(r,s);creates a new tree with left subtree r and right subtree s. Insert the new tree back into the priority queue. This function stops when there is only one tree in the priority queue. After taking the first tree r out of the priority queue, check whether the priority queue is empty. If so, then tree r the Huffman tree. Return it.
| |||
|
10. Make 'main' build a Huffman tree.
In huffman.cpp, modify 'main' so that it builds the huffman tree and, if tracing is turned on, shows the resulting tree. Test your program. Does it seem to create a sensible Huffman tree? | |||
|
11. Write a function to build a Huffman code.
In huffman.cpp, write a function 'buildCode' that takes the Huffman tree t and an array 'Code' that can hold 256 null-terminated strings. This function should fill in the 'Code' array so that, if character c occurs at a leaf in t then Code[c] holds the code of c, as a null-terminated string. If character c does not occur in tree t, then Code[c] should be NULL. Your function will need to have the following parameters.
If t is a leaf holding character c, then set Code[c] to prefix (since the code for a bare leaf is an empty string). Pay attention to where your strings are stored. Do not store a pointer into a function's run-time-stack frame in the code array! Remember that the frame is destroyed when the function returns. You would do well to store a copy of prefix. If t is not a leaf, then buildCode should call itself on the left and right subtrees of t. The prefix parameter for the call on the left subtree should be prefix with '0' added to the end. The prefix parameter for the call on the right subtree should be prefix with '1' added to the end. (You can create local arrays in buildCode and copy prefix into them using strcpy. Then concatenate "0" to the end of one and "1" to the end of the other using strcat.)
| |||
|
12. Write a function that shows the Huffman code.
In trace.cpp, write a function that shows the code from a code array when tracing is turned on. When showing a character, use your function that shows the character's description. In huffman.cpp, make 'main' build the code and, if tracing is turned on, show the code. Test what you have so far. Does it look right? If character 'a' occurs more often than character 'b', then the code for 'a' must be no longer than the code for 'b'. | |||
|
13. Get modules for reading and writing binary files.
The goal is to pack 8 bits into each byte. But before doing that, take a simpler approach where you write each bit as a character so that you can read it. After everything seems to work you can change it so that it writes a binary file instead. Get files binary.h, binary1.cpp and binary2.cpp. They provide the following tools for writing files.
Both files binary1.cpp and binary2.cpp have the same interface, described by binary.h. File binary1.cpp writes a text file, writing character '0' to represent bit 0 and character '1' to represent bit 1, allowing you to read the output with a text editor, but not actually compressing. File binary2.cpp writes a binary file, packing 8 bits into each byte. | |||
|
14. Write a function that writes a binary description of a tree.
In huffman.cpp, write a function that writes a description of a given tree into a given open binary file (type BFILE*). Note that this is not the same as your trace function that writes a tree for debugging.
Modify 'main' so that it opens the second file name in the command line as a binary file for writing. Then it writes the Huffman tree to the binary file and closes the file. | |||
|
15. Create file unhuffman.cpp.
File unhuffman.cpp will be the program that uncompresses a file. Copy the template into it. Make unhuffman.cpp include "trace.h". Make 'main' begin by turning tracing on or off, depending on the command line. (You already have a function that does that.) | |||
|
16. Write a function that reads a binary description of a tree.
Write a function in unhuffman.cpp that reads a tree whose description is in a given open BFILE* file, and returns the tree. Keep it simple. To read a tree, start by reading a bit. If the bit is a 1, you are looking at a leaf. Read the character (a byte) and build a leaf holding that character. But if the bit is a 0, then you are looking at a nonleaf. Read the left subtree then the right subtree.
Use the following for reading the binary file, also described by binary.h.
Modify 'main' in unhuffman.cpp so that it opens the compressed file for reading, reads a tree, closes the binary file and then traces the tree, if tracing is turned on. Clearly label the tree in the trace. The binary file to read is argv[argc − 1]. When you link unhuffman.cpp, it is critical that you use the same implementation of binary.h as for huffman.cpp. Either link both with binary1.cpp or both with binary2.cpp. | |||
|
17. Test what you have so far.
You will need a compressed file written by huffman, holding a description of a tree. Your huffman program should write a description of the tree into the binary file and your unhuffman program should read it back correctly. | |||
|
18. Write a function that does the compression.
In huffman.cpp, write a function takes the array of character codes, a binary file that is opened for writing, and the name of the file to read. It should reread the input file and write the code for each character that it reads into the open binary file. Modify 'main' in huffman.cpp so that, after writing the tree to the binary file, it calls the new function to write the encoded characters. Note. You will need to write a string of digits (all either '0' or '1') to a binary file. No function is provided to you that does that job. What should you do? Be sure to write 0 or 1 to the binary file, not '0' or '1'. Note. Do not close the binary file between writing the tree and writing the character codes. Only close it after doing both steps. | |||
|
19. Write a function that reads one character code.
In unhuffman.cpp, write a function that reads the code for a single character and returns the encoded character, as an integer. If it encounters EOF in the binary file, this function should return EOF. This function will take two parameters, the Huffman tree and a binary file that is open for reading. As you read each bit, move down the tree in the appropriate direction. When you hit a leaf, you have read a complete character code, and the character in the leaf is the character that the code stands for.
| |||
|
20. Write a function to do the decompression.
In unhuffman.cpp, write a function that repeatedly reads character codes from the binary file and writes the characters whose codes were read out to the uncompressed file. Keep reading character codes and writing the corresponding character into the uncompressed file until the end-of-file is reached. This function needs to be passed: the open binary file to read; the name of the file to write; and the Huffman tree, needed for decoding. So pass it exactly that information, not something else. | |||
|
21. Test both programs.
If you compress a file and then uncompress it, do you get back exactly what was in the original file? Try a file that contains tabs, spaces and has more than one line. Try some non-letter characters too. You can be sure that I will do that when I test your programs.
| |||
|
22. Submit your work.
Once you are convinced that everything is working, submit your work. | |||
Start each file from the standard template.
Submit all of the files that your programs need. Do not assume that I already have them.
Pay attention to warnings. In the past, many students have submitted programs that get serious warnings that point to serious mistakes in the program. I immediately know where to look for a serious mistake. You should too.
The comments at the beginning of huffman.cpp and unhuffman.cpp should make it clear how to use each program. Say what the command line should look like.
Indent sensibly. In the past, many students have been lax about indentation, presumably because they started too late and did not believe the wisdom of decades of software development that it is sensible to keep the program well-indented while working on it.
Use sensible function, parameter and variable names. A function that shows a string should not be called showChar. A variable that is an array of frequencies should not be called charArray.
Huffman and unhuffman each get the names of files to open from the command line. Be sure not to read or write files with fixed names. For example, do not assume that the files are called data.txt and data.cmp. If you do, your program will not work when I test it. It is not my job to fix your work.
Be sure to check for nonexistent files.
Only do tracing when tracing is turned on by option -t on the command line. Remember that -t occurs before the file names, if it occurs at all.
Follow the coding standards. Do not become lax on those.
Write clear, concise and correct contracts for every function and clear, complete comments for every type that you create. Make sure that the contract is correct. The function must do what the contract says it does. The function that counts character frequencies does not count "the number of frequencies of a character that occurs in a file." Each character only has one frequency. It does not do something for one character. Don't say that a function "sorts a Huffman tree." Read your contracts. Be critical of them.
Do not write more than one loop in one function body. Do not use one loop to emulate two nested loops.
String constants have type const char*. If a function takes a null-terminated string as a parameter, and the function does not change that string, make the parameter have type const char* so that you can pass a string constant as that parameter.
Do not do a
You should never cast a pointer to an array of type T and say to treat it as a pointer to an array of type R where T and R are different types. The compiler will let you do it because it assumes that you are an expert. You aren't an expert yet.
An empty string is written "". An empty string is not the same as NULL.
The standards require you not to use C++ type string. Don't use it.
If you get a memory fault, use a debugger, such as gdb, to find the error. If the fault occurs when you run huffman, then start huffman with command
gdb ./huffmanBe sure that you have compiled huffman with option -g. At the (gdb) prompt, type
run -t infile outfilewhere infile is the file to read and outfile is the file to write. At the memory fault, gdb will show exactly where the program is at the time. Do a backtrace (command bt) to see the run-time stack. Do command print v to print the value of a variable. Look at variables whose values could lead to a memory fault. Pointer 0x0 is a NULL pointer.
Watch out for memory leaks. This has been a frequent problem in the past.
To create a pointer variable p of type char* that you intend to set equal to something later, write
char* p;Don't write
char* p = new char;That allocates one byte, which leaks away as soon as you change p to point to something else.
Don't use fixed array sizes when it is not necessary. If it is easy to compute how large an array needs to be, then compute the size.
If you want to talk about a space character, write ' '. Do not write 32. If you want to talk about character '0', write '0', not 48. If you want to talk about a newline character, write '\n', not 10. You should see a pattern here.
If you want to say EOF, write EOF, not −1.
Do not use long lines. Limit lines to 80 characters. Do not put non-7-bit-ascii characters in your comments. To write a single quote, use the apostrophe character. Don't try to be fancy. If a character is not on the keyboard, don't use it.
If s does not change, do not recompute strlen(s) each time around a loop. Computing strlen(s) requires scanning through s to find its end.
To turn in your work, log into xlogin, change your
directory for the one for assignment 8, and
use the following command.
~abrahamsonk/2530/bin/submit 8 huffman.cpp unhuffman.cpp tree.h trace.cpp trace.h pqueue.h pqueue.cpp
If you created any additional files, such as tree.cpp, add those to the list.
After submitting, you should receive confirmation that the submission was successful. If you do not receive confirmation, assume that the submission did not work.
Command
~abrahamsonk/2530/bin/submit 8
will show you what you have submitted for
assignment 8.
You can do repeated submissions. New submissions will replace old ones.
Late submissions will be accepted for 24 hours after the due date. If you miss a late submission deadline by a microsecond, your work will not be accepted.
To ask a question about your program, first submit it,
but use assignment name q8. For example, use command
~abrahamsonk/2530/bin/submit q8 huffman.cpp unhuffman.cpp tree.h trace.cpp trace.h pqueue.h pqueue.cpp
Include a data file if appropriate. If you don't have all
of those files, submit what you have.
Then send me an email with your question. Do not expect me to read your mind. Tell me what your questions are. I will look at the files that you have submitted as q8. If you have another question later, resubmit your new file as assignment q8.