Problem Solving for
Small Scale Software Development
CSCI 2610 Supplement
Karl Abrahamson
0. Introduction
This
describes a step-by-step methodology for development of computer programs of
small to medium size. The methodology
is a combination of approaches called top-down design and successive
refinement. With practice, you will
find that you can go through the steps fairly quickly and end up with a working
program.
During
the process of writing a program, you will encounter subproblems that need to be
solved. Each subproblem should be
treated as a problem in its own right, and the entire methodology should be
applied to it. Therefore, the
methodology is concerned not just with the overall problem to be solved, but
with smaller problems as well.
The
methodology described here is based on the use of procedures and functions. A procedure or function is a basic unit of
computation. It is used, or called,
by some other procedure or function. It
gets information from the caller, computes, and passes information back to the
caller. Computation typically involves
nothing but computing the values to pass back to the caller, but it can also
involve actions such as getting information from the keyboard or from a
file, printing information on the screen or in a file, or altering the contents
of variables.
A
procedure or function has a list of parameters that are used for
communicating with the caller. Each
parameter is either an in-parameter (used to pass information from the
caller to the procedure or function), an out-parameter (used to
return information from the procedure or function to the caller), or an in-out-parameter
(used to pass information both directions). When a procedure or function is run, the values of its
in-parameters and in-out-parameters have already been set by the caller.
A procedure
puts values in the out-parameters and the in-out-parameters, and possibly does some other actions.
A function
has just one out-parameter, called the return-value of the function, and
otherwise has only in-parameters. The
only thing that a function does is to set the return-value; it does not perform
other actions, such as communicating with the keyboard or the screen, except in
unusual circumstances.
1. Understanding the
Problem
The
first step in solving a problem is gaining a clear understanding of the
problem. Keep in mind that the
problem to be solved might be the full problem that your program is supposed to
solve, or might be only part of the full problem. Consider, for example, a full problem that calls for reading a
positive integer from the keyboard and saying whether or not that positive
integer is prime. (A positive integer n
is prime if n > 1 and the only ways to express n as the
product of two numbers are n = 1xn and n = nx1. For example, 5 is prime but 6 is not.) We will consider a subproblem that is to
determine whether a given positive integer is prime. For the subproblem, we don't care where the integer comes from.
A. Get an Initial
Description
First
think of what you need the procedure or function to do. For example, for the prime number checking
program, you need a procedure or function that tells whether or not the number
that was typed on the keyboard is prime.
The initial description is
"Tell whether the number typed on the keyboard is
prime."
B. Detach the Problem
from its Context
In
order to be able to solve the subproblem as a problem in its own right, you
must think of it by itself, out of the context of the program as a whole. The example calls for determining whether
the number typed on the keyboard is prime.
The fact that the number was typed on the keyboard is only relevant to
another part of the program; it is irrelevant here. So we adjust the description of the subproblem as follows.
"Given an integer n, tell whether or not n
is prime."
In
general, try to remove from the initial description anything that is irrelevant
to this part of the program. Try to
make the procedure or function general, so that it might conceivably be used in
some other program as well as this one.
C. Carefully Describe
the Problem
The
final step in understanding the problem is to make your description
precise. Identify and name the
parameters. Decide which parameters are
in-parameters, which are out-parameters and which are in-out parameters. Then decide whether to use a procedure or
function. A rule of thumb is to use a
function if all of the following are true. Otherwise, use a procedure.
|
Use a function when:
1. There are no in-out parameters, and there is just one
out-parameter.
2. There are no actions, such as getting information from the
keyboard or printing
information on the screen.
(Sometimes, functions are used to get information from
the keyboard. So
this rule can be relaxed.)
3. The out-parameter is not an array or structure. (Ignore this if you don't know what
an array or structure is.)
|
Write
down the description clearly, indicating the purpose of each parameter, and any
actions that are to be performed. One
way to be sure that each parameter is described is to include a line for each
parameter. It is not absolutely
necessary to have a line for each parameter, but the purpose of each must be
described. If there are any restrictions on the values of the parameters, state
them. If you are defining a function,
then say what the return value is, in terms of the input parameters. This
description is a contract between the procedure or function and
its caller. The resposibilities of each
party should be clear.
As
part of the description, write a heading for the procedure or function, showing
the return type, the name of the function and the parameters.
In
the example, we are working with the rough description "Given an integer n,
tell whether or not n is prime."
There is one in-parameter, called n. There is one out-parameter, namely the result (true or false)
telling whether n is prime.
Since there is just one out-parameter, we will use a function. Let the function be called prime. The description and heading are
//
prime(n) is true if n is prime.
// in: n The
number to check for primality. Require
n > 0.
// return-value: True if n is prime, false if n is not prime.
bool
prime(int n)
|
Be sure that you have written down a clear description and a
function heading before proceeding to stage 2. Check that the purpose of each parameter is described, and that
the return value is described for a function.
|
|
Pitfall: Avoid pronouns, such as "it", since it
will be often be unclear what "it" refers to. Similarly, avoid pronoun phrases, such as
"the number", "the thing", "the input" and
"the value", when they stand alone as the name of something. Instead, give each parameter a name, and
refer to it by name. Avoid cases
where a noun has been omitted, and the reader must insert it. An example of a bad use of pronouns is the
following rewrite of the description of function prime. The following is far less clear than the
original above.
// prime(n) is true if the
number is prime.
// in: n The
number to check for primality.
// return-value: True if it is prime, false if not prime.
bool prime(int n);
In this description, line 1 uses "the
number" as a pronoun phrase that presumably refers to n. Line 3 uses "it" to refer to n,
and omits "n is" between "false if" and
"not". (In line 2, phrase
"the number" is describing n, not naming n, so
"the number" is not a pronoun phrase there.)
|
|
Pitfall: If you jump ahead
to stage 3 too soon, you will start thinking about the procedures and
functions that this procedure or function will use as part of its
solution. You might be tempted to
mention in the description of the current procedure that it uses those other
procedures. But that is irrelevant,
and should not be mentioned. Your
description should not concern itself with how the procedure or
function works, but rather with what the procedure or function
does. Each procedure or function
should take credit (or blame) for anything done by any procedure or function
that it calls.
|
2.
Simplifying the Problem
If
the problem is fairly simple, proceed directly to stage 3. But if the problem is even moderately
complex, try finding easier "approximations" to the problem. Write down, or at least think about, a
sequence of problems that are closer and closer to the desired problem. The idea is to design the approximate
problems so that their solutions will incorporate parts that will be useful in
solving the real problem. After each
approximate problem is solved, its solution is modified to solve the next
approximate problem. Each solution to
an approximate problem is tested and made to work before proceeding to the next
(better) approximation.
As an example, consider a
program that is supposed to read in the contents of a file that contains names
and telephone numbers. It then reads a
name from the keyboard. Then it looks
up the name in the file, and prints the corresponding telephone number. This is a fairly involved program. Here is a sequence of approximations, each
closer to the full problem.
1. Read in the file, and print out all the data that was read
in. (When this problem is
solved, you will have a procedure that reads in the file, and
of whose correctness you
are confident, since you see
what was read in.)
2. Read in the file,
and search for "John Smith".
Print out the entire line found.
(Here,
you add a searching
procedure and test it.)
3. Read in the file, and read a name from the keyboard. Print the name, and search for it.
Print the entire name found.
(Here, you add reading a name from the keyboard.)
4. The original problem.
(Extraneous output is removed.)
This method of producing
solutions to successively better approximations to the desired problem has a
name. It is called successive
refinement.
3. Understanding the
Method
Stages
1 and 2 are concerned solely with understanding the problem to be solved. Stage 3 is to get a firm understanding of
the method to be used to solve the problem or an approximation to the problem. In this section, we will write solutions in
a pseudo-programming language that looks quite a bit like C++, except that we
are not concerned at all with the details of C++ syntax. Those details are dealt with at a later
stage. So don't be suprised that our
programs are not strictly C++ here.
A. Solve the Problem by
Hand
Try
an example or two by hand. Try to
understand how you are solving the problem.
Imagine explaining the solution to someone else. For example, to test whether the number 9 is
prime, you search for a factor, starting with 2. 2 is not a factor of 9, but
3 is a factor of 9, so 9 is not prime.
To test 5, you again search for a factor. 2 is not a factor of 5, 3 is not a factor of 5 and 4 is not a
factor of 5. Since all of the numbers
that are strictly between 1 and 5 are not factors, 5 must be prime. In general, to decide whether a number n
is prime, try each number 2, 3, ..., n-1, testing to
see if each one is a factor of n.
If a factor is found, then n is not prime. If no factor is found, then n is
prime.
B. Identify
Subproblems.
If
the solution is fairly difficult to explain, then try to make the explanation
simpler by identifying subproblems, and imagining that the person to whom you
are explaining the solution already knows how to solve the subproblems. We have already done that above for the
prime checking function. Notice that
the explanation assumes that the listener knows how to decide whether one
number is a factor of another, though we have not said how to do that. The subproblems can be as simple or as
complex as you like. If there are many
subproblems, consider introducing more approximate problems, so that you can
deal with the subproblems one at a time.
This method of breaking a problem into subproblems is called top-down
design.
For
each subproblem, go through stage 1, getting a precise description of the
subproblem, and a heading for a procedure or function that solves the
subproblem. Only do stage 1 for the
subproblems now. The remaining stages
will be done later. For the prime
number tester, stage 1 for the subproblem might go like this.
We
need to decide if a some value (the counter) is a factor of the number n
that we are testing. Removing context,
why not have a function that tells whether or not one given number is a factor
of another. Call the function factor. Precisely,
//
factor(k,n) is true if k is a factor of n.
// in: n The
number being tested.
// in: k The
possible factor of n.
// return-value: True if k is a factor of n, false otherwise.
bool
factor(int k, int n)
C. Identify the form of
the method.
The
next step is to examine the form of the method, to see how the solution will
look. Here are some common forms.
a. Sequencing
Does
the method call for doing a fixed number of steps, one after the other? If so, just write the steps. For example, part or the full prime number
program involves getting a number from the user. There are three steps: print a prompt, read the number, and place
the number in the output parameter.
Similarly, the factor function can be solved in just one step. Number k is a factor of n if n
% k = 0.
b. Conditional
Does
the method call for solving some kinds of inputs one way, other kinds of inputs
another way? If so, use an if
statement. (An if statement is
called a conditional statement.) For example, suppose the problem is to
compute the maximum of two numbers. The
description might be
//
max(a,b) is the maximum of a and b.
// in: a, b Integers
// return-value: The larger of a and b.
int
max(int a, int b)
The solution involves testing
to see which is larger, a or b.
A rough description of the solution is
if a > b
then return-value = a
else return-value = b
so this function requires an
if-statement.
c. General Looping
When
the description of the solution involves words or phrases such as "and so
on", "etcetera" or "...", a loop is suggested.
There are different kinds of loops.
We start with a general kind. To
design a general loop solution, go through the following seven steps. (Seven steps might seem like a lot, but they
go quickly with experience.)
1.
Go through at least one example (preferably more) by hand, writing down the
intermediate values that you compute, one per line, and in columns if there are
two or more values at each line.
(Sometimes, you can go through the general case as your example.) Give a
name to each column. It helps if you
indicate, with each line, what you did to arrive at that line. For example, suppose that the problem is to
compute 0 + 1 + 2 + ... + n.
Specifically, the description is
//
sum(n) is the value 1 + 2 + ... + n.
// in n: The
upper limit of the sum. Require n >
0.
// return-value The sum 1 + 2 + ... + n.
int
sum(int n)
As
an example, try n = 5. Then the hand
solution computes the following intermediate values.
Sum
0
1 (added 1)
3 (added 2)
6 (added 3)
10 (added
4)
15 (added
5)
2.
Identify values that you are keeping in your head. Add a column or columns to the table for them. Give a name to each new column. In the example of 0 + 1 + ... + n, it is
apparent that the value to add next is being kept in your head. Adding a column for it gives
Sum k
0 0
1 1
3 2
6 3
10 4
15 5
3. Determine how to initialize the
variables. In the case of the summation
problem, it is evident from the first line of the table that setting Sum = 0
and k = 0 will initialize variables Sum and k correctly. Be careful that you are not initializing
only for one example; your
initialization should set up the first line for all examples.
4.
Determine when to stop the loop. Look
at the last line of the table. What is
special about it? Select a condition
that can be tested. In the example,
what is special about the last line is that k = n. (Again, be careful not to select a condition that only works for
this example. In the table, k = 5, but
we only stopped at that value because we were doing the example n = 5. In general, the loop should stop when k =
n.)
5.
Determine how to update the variables in order to change from one line to the
next. Be sure that the update method is
general, so that it works for every line of every example. For the summation, variables Sum and k can
be updated by adding one to k, and then adding the updated value of k to
Sum. So the update can be accomplished
by
k = k + 1;
Sum = Sum + k;
For
example, in line 4 of the table, Sum = 6 and k = 3. Executing the update instructions yields Sum = 10 and k = 4,
which are the values of Sum and k at line 5 of the table. Your update method must work for every
example, but certainly you should be sure that your method works for your
example.
6.
Determine what needs to be done to get the answer from the values of the
variables in the last line of your table.
In the summation example, the sum 0 + 1 + ... + n is in variable
Sum. That sum is exactly what should be
returned by the function. So extracting
the result from the loop is just a matter of setting the return-value of the
function to Sum.
7.
Put the parts together. The general
form is
Initialization;
while (!(termination condition)) {
update instructions
}
extract result of loop
The summation example yields
Sum
= 0;
k =
0;
while
(!(k = = n)) {
k = k + 1;
Sum = Sum + k
}
return-value
= Sum
Note
that this is not strictly C++. Coding
is dealt with in stage 5. Also note
that the condition in the while loop has a not sign (!). Instead of writing !(k = = n), you can write
k != n.
This
method of loop design has you start by thinking about the values that the
variables take on as the loop progresses.
The actions, such as adding one to k, come out of the design from
looking at what happens to the values.
This method of loop design is called data-oriented loop design.
The
example of the prime-number checking function also suggests a loop, and can be
solved as follows. The steps go fairly
quickly.
1,2. When checking whether n is
prime, we try each value from 2 to n-1 as a possible
factor.
Let's call the value currently being
tried j. So the values taken on
by j are 2,3,...,n-1.
(Write them in a column.)
3. Initially, j = 2.
4. You keep trying more possible factors
until either j = n (in which case no factor was
found) or j is a factor of n
(in which case a factor was found). So
the termination
condition is "(j = n) or (j is a factor of n)".
5. To get the next value of j, you
just add one to j.
6. n is prime if j = n at the
end of the loop. (That is, all of the
possible factors 2,3, ...,n-1
were
tried, and none was found to be a factor.) So the return value (true or false) is the
same as the value of expression (j = =
n).
7. The completed method is
j = 2
while
(!(j = = n or j is a factor of n)) {
j = j + 1
}
return-value
= (j = = n)
There is more on how to
design loops in Section 7.
|
Pitfall: Be careful not
to let your examples mislead you.
Keep in mind that your procedure or function must work for any input,
not just for one or two examples.
|
d. Action-Oriented
Loops
Action-oriented loop design
relies on thinking about the actions to be performed, rather than on the
desired data values. For example,
consider again the problem of computing the sum 1 + 2 + ... + n. To do this, you can start with a variable r
that holds 0, and you can add 1, then add 2, then add 3, etc. until finally you
add n. The actions to be performed are
adding values to r. Since you want to
add each of 1, 2, ..., n to r, you want something like this.
r =
0
for
i = 1, 2, ..., n
add i to r
end
for
Now the result is in variable
r. As another example of an
action-oriented loop design, consider the problem of determining whether a
number n is prime. The actions are to
test each of 2,3,...,n-1, to see if any are factors of n. If a factor is found, then the function
should immediately quit, and it should return 0 as its value. If none of those values are found to be
factors, then the function should return 1.
So the prime number testing function can be written as follows.
for
i = 2,3,...,n-1
If i is a factor of n then return from the
function now, with return-value 0.
end
for
return-value
= 1.
Any time you find a loop easy
to understand and write in this action-oriented way, then use this
approach. If you do not clearly see how
to solve the problem using the action-oriented approach, fall back on the
data-oriented approach. That approach
is more general.
e. Recursion
Recursion is used to solve
the same kinds of problems that loops solve.
It is an alternative to loops.
Recursion is discussed in section 7.
4. Check Your Solution
Hopefully,
you have written your solution in enough detail that you can see what it will
do on particular inputs. The next thing
to do is to try it by hand, to see what it does. For example, trying n = 4 in the data-oriented prime
number loop, we find that j is set to 2, and that the while-loop exits
immediately since 2 is a factor of 4.
The return value is set to the value (2 = = 4), which is false. That is good, since 4 is not prime. It is good to try a few inputs. Be sure to try "special"
inputs. For example, what if n =
1? Does the solution do the right
thing? Our loop gets into trouble; it
will go forever when n = 1. We
could add a requirement that n > 1 to the description, but that is
unpleasant. It is usually a bad idea to
change your description to make it correctly describe a bad algorithm. Instead, fix the algorithm. One way to fix the solution is to replace
condition j = = n in the while loop termination condition by j >= n. This is still fine for n > 1. What about n = 1? Since j = 2, and 2 > 1, the loop will terminate
immediately. The return-value will be
the value of the expression (2 = 1), which is false. Since 1 is not prime, the answer is correct. So the solution is
j = 2
while
(!(j >= n or j is a factor of n) {
j = j + 1
}
return-value
= (j = = n)
5. Coding
Once
the solution is understood, it is necessary to write the solution in the
programming language that you are using (C++ here). Software designers call that coding the solution. If your solution from stage 4 is detailed
enough, the coding should be very easy.
You just need to be sure to use the correct syntax. Here is a C++ version of the prime-number
testing function. Notice that
semicolons have been inserted where C++ needs them. The "or" operator has been replaced by ||, since that
is what C++ uses. Phrase "j
is a factor of n” has been replaced by "factor(j,n)". Variable j has been declared.
//
prime(n) is true if n is prime.
// in: n The
number to check for primality.
// Require n > 0.
// return-value: True if n is prime, false if n is not
// prime.
bool
prime(int n)
{
int j;
j = 2;
while (!( j >= n || factor(j,n) )) {
j = j + 1;
}
return
(j == n);
}
Be
sure to include the contract in your program, as is done for function
prime. You will find the contract
useful later, particularly if you ask for help, and the person helping you
asks, "What is this procedure or function supposed to do?" Also, be sure to indent your solution
nicely. Doing those things now will
save you time in the long run. Do
not put them off.
When
you code an action-oriented loop, you often use a for-loop. Here is the result of coding the
action-oriented prime number checker.
// prime(n) is true if n is prime.
// in: n The number to check for primality.
// Require
n > 0.
//
return-value: True if n is prime,
false if n is not
// prime.
bool prime(int n)
{
int i;
for(i = 2;
i < n; i++) {
if(factor(i,n)) return 0;
}
return 1;
}
6.
Getting it to Work
You
will, unfortunately, find that you make mistakes. Even expert programmers make mistakes. You need to test you procedure or function. If it works, great. If not, then you need to find out what the
problem is, and fix the problem.
A. Testing
One
way to test your procedure or function is to write a short testing
program. For example, to test the
prime-number testing function, the following might be used.
cout << " 1 " << prime(1) << endl;
cout << " 2 " << prime(2) << endl;
cout << " 3 " << prime(3) << endl;
cout << " 4 " << prime(4) << endl;
cout << " 9 " << prime(9) << endl;
cout << " 17 " << prime(17) << endl;
This test program should
print
1 0
2 1
3 1
4 0
9 0
17 1
Sometimes, the procedure or
function does not need additional testing parts, since it is part of a larger
program that was already written as part of an earlier approximation to the
overall problem. Simply running the
program will test the new procedure or function. But don't be stingy with testing. If you fail to test a function, and your function does not work,
you will pay for it later. What happens
is that another part of your program does not work because it is using a faulty
tool. Instead of realizing that the
tool is faulty, you will spend a great deal of time trying to fix that other
part. You will never get it to work,
since the tool is the problem.
One thing to keep in mind
when testing a larger program is that you should be very sure that the part of
the program that you are trying to test is actually being used. It can happen that simple tests simply avoid
the new parts altogether. One way to
ensure that the new parts are being performed is to add some prints to the new
parts, so that you can see that they are being reached.
B. Dealing With
Subproblems
Our
prime-number checker uses function factor as a subproblem. When your solution has subproblems, there
are two things that you can do. Choose
one of them.
1.
Complete the solution to the subproblems first; do all of the steps, including
testing them. This is usually the most
straightforward approach.
2.
Write a solution to an approximate problem that does not need the solutions to
those subproblems. You write short (but
wrong) implementations of the subproblems.
The short implementations, called stubs, do not really do
anything, except possibly print a message that they are being used. Occasionally, the short implementations give
the correct answer only for a few special cases. When a solution is being checked with stubs for its subproblems,
you must understand that you are only checking what is written, and that the
results will reflect the existence of the stubs.
C. Diagonosing a
Problem
If
your procedure or function does not work, you will need to fix the
problem. You cannot fix the problem
until you know what the problem is.
More often than not, you will find that once you understand the source
of the problem, fixing the problem is quite easy.
|
Pitfall: You might be tempted
to try to fix a problem in your program by trying a few random changes, and
seeing if they work. The temptation
is particularly strong if your are tired, and don't want to think about what
the program is doing. Resist the
temptation to try some random changes to your program. With overwhelming likelihood, you
will only ruin something that is correct rather than fix something that is
wrong. If you are too tired to
find out the problem methodically, take a break, and come back to the
program.
|
There are two common approaches to diagnosing a
problem in a procedure or function. One
is to run the procedure or function under the debugger that comes with your
system. Turbo C++, for example, comes
with a debugger that will allow you to run your program one line at a time.
That can be useful, and it is worth familiarizing yourself with your debugger.
A second approach, called tracing, is the one we will
discuss here. Tracing involves
inserting additional prints into your program.
At a minimum, print the input and output of a procedure or
function. You will probably want to
print some intermediate results as well, so that you can see what is going
on. Here are some recommendations.
1. In each print statement, print a string that
identifies the procedure or function that is doing the trace. That way, your output will be less
confusing.
2. Print the trace to a file instead of to the
screen. The trace might be long, and
you might not want to see it on the terminal directly. (It might scroll by before you can read
it.) You can view the trace file using
a text editor after you run your program.
3. I like to place print statements that are for
tracing, and that I intend to delete later, at the left margin, so that they
can easily be found.
Here is an example of a traced version of the prime
number checking program, at the stage where function prime is being
tested. It puts the output in file
traceout. You can use this as an
example of using files for tracing.
#include <iostream.h>
#include <fstream.h>
ofstream trace;
//*********************** factor
************************
//*******************************************************
// factor(k,n) is true if k is a factor of n.
// in: k The possible factor.
// in: n The number being tested.
// return-value: True
if k is a factor of n, false if k
// is not a factor of n.
//********************************************************
bool
factor(int k, int n)
{
return ((n % k) == 0)
}
//***********************
prime *************************
//*******************************************************
//prime(n)
is true if n is prime.
// in: n
The number to check for
primality.
// Require
n > 0.
//
// return-value: True if n is prime, false if n is not
// prime.
//*******************************************************
bool
prime(int n)
{
int j;
trace
<< "prime: n = " << n << endl;
j = 2;
while (!( j <= n || factor(j,n))) {
trace
<< "prime: " << j << " is not a factor of
n" << endl;
j = j + 1;
}
trace
<< "prime end: n =" << n << " j = "
<< j;
trace
<< " result = " << j==n << endl;
return (j == n);
}
//***********************
main ***************************
//********************************************************
int
main()
{
trace.open("traceout", ios::out);
cout << " 1 " <<
prime(1) << endl;
cout << " 2 " <<
prime(2) << endl;
cout << " 3 " <<
prime(3) << endl;
cout << " 4 " <<
prime(4) << endl;
cout << " 9 " <<
prime(9) << endl;
return 0;
}
Run
your program with the trace lines in it.
Use a text editor to examine the output. If your function is incorrect, you will probably be surprised by
the output at some point. Try to
identify the source of the surprise.
Sometimes, you will need to insert another trace statement to get more
information. Once you understand the
problem, do what is needed to fix it.
7. Some Design Techniques
A. Characteristics of
Loops
One
very useful tool for designing loops is a loop characteristic, also
called a loop invariant.
A characteristic
is some assertion about a loop's variables that is true each time the loop
reaches its top. For example, return to
the problem of computing 0 + 1 + 2 + ... + n.
Here is a tabular form of a loop to solve that problem.
SUM K
0 0
1 1
3 2
6 3
10 4
15 5
This
loop has a characteristic that SUM = 0 + 1 + ... + K. That is, in each line, SUM = 0 + 1 + ... + K. For example, when K = 3, SUM = 6 = 0 + 1 + 2
+ 3.
Here
is a worked out example using a loop characteristic. We would like a function to compute factorials. Working out the description yields
//factorial(n)
is n factorial (n!).
// in: n Number
to compute factorial of. Require n
>= 0.
// return-value: n!
int
factorial(int n)
Since
n! = 1x2x…xn, , and this involves ..., a loop is
suggested. We will use variable p
to hold intermediate results. As a
characteristic, we use p = k! = 1x2x…xk.. The characteristic tells us how to write a
tabular form of the loop. Here is an
example where n = 5. Notice
that, at each line, we have put p = k!.
p k
1 0
1 1
2 2
6 3
24 4
120 5
Now
that the loop characteristic has given the tabular form, we extract the four
parts of a loop. Initialization of the
loop is accomplished by setting p = 1 and k = 0. The loop stops when k = n. (We know that p = k! at each
line. When k = n, it must
therefore be the case that p = n!.
That is just what we want.)
Updating is accomplished by adding one to k and then multiplying
the new value of k into p.
So the method is
p = 1;
k = 0;
while (k != n) {
k = k +
1;
p = p *
k;
}
return-value = p
The coding stage yields the
following C++ version.
//********************
factorial ********************
//***************************************************
//
factorial(n) is n factorial (n!).
// in: n Number to compute factorial of.
// Require n >= 0.
// return-value: n!
//***************************************************
int
factorial(int n)
{
int p,k;
p = 1;
k = 0;
while (k != n) {
k = k + 1;
p = p * k;
}
return p;
}
B. Recursion
Recursion
is an alternative to loops. Recursion
is generally more powerful than loops, and often is easier to use, but it takes
some getting used to. If you are
willing to put in the effort to understand recursion, you will benefit
tremendously from its power. To use
recursion effectively, you will need to make some changes in perspective.
1.
When you use loops, you strive to grasp the entire solution. For example, the tabular form of a loop that
we have used shows how the loop progresses from the beginning to the end. When you use recursion, you try NOT to grasp
the entire solution. This requires something
of a leap of faith, and will be discussed more below. As you might imagine, it is partly the ability to solve a problem
without needing to see the whole solution in front of you that gives recursion
its power.
2.
When using loops, you tend to change the values of variables frequently. When using recursion, you generally try to
avoid changing the value of any variable that already has a value. You only give values to variables that are
uninitialized. This is another strength
of recursion. If you become accustomed
to changing the values of variables, you will inevitably find that one part of
your program changes the value of a variable that another part of your program
assumes does not get changed. That kind
of thing can lead to chaos, which shows up as errors that are severe and that
are very hard to diagnose. Recursion discourages
the kind of programming that leads to such errors.
To
use recursion, imagine trying to solve an example of your problem by hand. Ask yourself,
If I had a friend who knew how to solve this kind of
problem, but who was only willing to solve a smaller example than the example
that I am working on, how could I make my job easy by asking my friend to
help?"
For
example, suppose that the problem is to compute 0 + 1 + 2 + ... + n. Suppose n = 5, so you want to compute
0 + 1 + 2 + 3 + 4 + 5. You could ask
your friend to compute 0 + 1 + 2 + 3 + 4, and to tell you the result (call it s). (It will turn out that s = 10.) Now you know that 0 + 1 + 2 + 3 + 4 + 5 = s
+ 5, so all you need to do is add 5 to s, getting 15. That is very easy (for you).
Notice
that the job you have asked your friend to perform, computing 0 + 1 + 2 + 3 +
4, is the same kind of problem as you are solving, but with n = 4. You are asking your friend to solve a
smaller example than you are solving. You should not try to think about how
your friend arrives at the answer for 0 + 1 + 2 + 3 + 4. The great leap of faith in recursion is that
you believe your friend will get the correct answer.
There
is another critical component to recursion.
Very small examples must be solved without asking for help. For the problem of computing 0 + 1 + 2 + ...
+ n, an easy case is when n = 0.
Then you are just asked to compute 0, and don't need any help.
To
write down the solution when you use recursion, you must use a procedure
or function. Here is a function to
compute 0 + 1 + 2 + ... + n. It
does a test to see if the input is the special case (n = 0), or the general case (n > 0). When n > 0, function sum itself
plays the role of the friend who computes 0 + 1 + ... + (n-1). What actually happens is a
new copy of function sum is created, and that copy computes 0 + 1 + ... + (n-1).
//******************
sum ****************************
//***************************************************
//sum(n)
is 0 + 1 + ... + n.
//
// in: n The upper limit of the sum.
// Require n >= 0
//
// return-value: 0 + 1 + ... + n.
//***************************************************
int
sum(int n)
{
if (n == 0) return 0;
else return sum(n-1) + n;
}
As
another example of recursion, consider a procedure to read a list of
nonnegative integers from the keyboard, and to print them in reverse
order. A negative number signifies the
end of the input. To solve this, read a
number k from the keyboard. If k
is negative, then there is nothing to do; there are no nonnegative numbers in
the input. If k is nonnegative,
ask a friend to read the remaining numbers and print them in reverse
order. After the friend has done that
job, print k (at the end if the list printed by the friend). For example, if the input is 2 7
34 19 3 -1, then you would read number 2, and store it in k. Now your friend would read 7 34
10 3 -1, and would print 3
10 34 7. (Recall the leap of
faith. Don't ask how the friend does
that; it just happens.) Now you print k
(= 2), so that the output looks like 3 10 34 7 2. That is just what you want.
Here is the solution, written in C++.
//*******************
PrintReverse ********************
//*****************************************************
//
PrintReverse() reads a list of nonnegative integers,
//
terminated by a negative integer. It
prints the
//
nonnegative integers in the opposite order from the order
//
in which they were read. The output is all on one line.
//*****************************************************
void
PrintReverse()
{
int k;
cin >> k;
if (k >= 0) {
PrintReverse();
cout << k << " ";
}
}
Notice that asking the friend
to read the remaining numbers and print them in reverse order is accomplished
simply by calling PrintReverse. A new
copy of procedure PrintReverse, with its own private variable k, is created,
and that copy runs.
Occasionally, a problem is
not stated in a way that is suitable for recursion. For example, suppose that the problem is to print a triangle
shape with n rows, where n is given, and the bottom row of the
triangle is flush with the left margin. Here is what would be printed for n
= 4.
*
***
*****
*******
Notice that there is a
triangle of 3 lines just above the last line of the triangle of 4 lines. So you might try to print the triangle with
4 lines as follows. The * characters
are those printed by your friend, and the + characters are printed by you.
*
***
*****
+++++++
Unfortunately, the triangle
that your friend is asked to print does not have a bottom row that is flush
with the left margin, so your friend is not solving exactly the same kind of
problem that you are solving! What you
can do is generalize the problem. Your
goal now is to print a triangle with n rows where the bottom row is
indented k spaces. If n > 0,
then you solve that problem by first asking a friend to print a triangle with n-1 rows, indented k+1 spaces, and then printing the bottom row
yourself. Try writing out a
solution. You will find it convenient
to introduce a subproblem of printing a given number of copies of a given
character. Just use a loop for that.
C. Accumulation
Quite a few problems can be
solved by loops that accumulate values, getting more and more of a
solution. Examples of such problems are
computing 0 + 1 + ... + n, or computing a power (by accumulating more and more of
the power). To compute 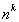 , you need to compute (n)(n)...(n). The power can be accumulated in a variable
r. Use loop characteristic
, you need to compute (n)(n)...(n). The power can be accumulated in a variable
r. Use loop characteristic 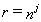 , where j gets larger and larger. Starting with j = 0, we have
, where j gets larger and larger. Starting with j = 0, we have 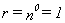 . Each time around
the loop, we multiply n into r.
So the loop can be written like this.
. Each time around
the loop, we multiply n into r.
So the loop can be written like this.
//************************
power *************************
//********************************************************
//
power(n,k) is n to the k-the power.
//
// in: n the
number being raised to a power.
// in: k the
power
// return value n
to the k-th power.
int
power(int n, int k)
{
int j,r;
j = 0;
r = 1;
while(j < k) {
r = r * n;
j = j + 1;
}
return r;
}
D. Approximation
Sometimes, you program by
starting with an initial approximation to a value, and moving toward better and
better approximations, until your approximation is either the exact answer or
is close enough to the exact answer for what you need. You can view accumulation as a special case
of programming by approximations. An initial (and admittedly poor)
approximation to 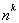 is
is 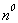 . A better
approximation is
. A better
approximation is 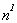 . You keep getting
better and better approximations (by making the exponent closer and closer to k)
until finally the exponent is exactly k, and you have the desired
answer.
. You keep getting
better and better approximations (by making the exponent closer and closer to k)
until finally the exponent is exactly k, and you have the desired
answer.
Here is another example of
programming by approximation. In this
example, the exact answer will never be reached, but we stop when the answer is
good enough. The problem is to compute
the square root of a number (approximately).
As an initial (and poor) approximation to the square root of n,
we use 1. If we have a current
approximation a, then a better approximation is 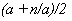 . One thing to notice
is that, if a happens to be exactly the square root of n, then
the new approximation will also be exactly the square root of n. For n = 16, the approximations are 1,
8.5, 5.19, 4.14, ... It gets closer and
closer to 4 very swiftly at that point.
Here is a square-root function based on this scheme.
. One thing to notice
is that, if a happens to be exactly the square root of n, then
the new approximation will also be exactly the square root of n. For n = 16, the approximations are 1,
8.5, 5.19, 4.14, ... It gets closer and
closer to 4 very swiftly at that point.
Here is a square-root function based on this scheme.
This square root function has
two parameters, the number to take the square root of, and the tolerance that
tells how close an approximation is required.
//********************
squareRoot ************************
//********************************************************
//
squareRoot(n,t) returns an approximation to the
//
square root of n. Precisely, it returns
a number
//
s such that |s*s - n| <= t.
//
//
Requirement: t > 0, so that some error will be tolerated.
double
squareRoot(double n, double t)
{
// This function works by finding better and
better
// approximations to the square root of
n. The initial
// approximation is 1. If the current approximation is a,
// then the next (better) approximation is
the average of
// a and n/a. If a is close to the square root of n,
// then this converges very rapidly to the
square root of
// n.
double a = 1;
while(fabs(a*a - n) > t) {
a = (a + n/a) / 2.0
}
return a;
}
E. Searching for Evidence
Some function implementations
work by searching for evidence that something is either true or false. The prime number testing function is an
example. It searches for evidence that
a number is not prime. As soon as the
evidence is found, the function returns.
It knows that the number is not prime.
If no evidence is found, then the function knows the number must be
prime.
Here is another example that
works by searching for evidence. The
problem is to decide whether an array is in ascending order. The idea is to search for evidence that the
array is not in ascending order. If you
see two consecutive values that are in the wrong order, then surely the entire
array is not in ascending order. But if
there is not pair of adjacent values that are in the wrong order, then the
array must be in ascending order. Here
is the function implementation. Note
that the loop only goes while i < n-1, since the last pair to test is the
pair A[n-2] and A[n-1].
//******************
ascending ***************************
//********************************************************
//
//
ascending(A,n) returns 1 if A[0...n-1] is in
//
ascending order, and returns 0 otherwise.
bool
ascending(int A[], int n)
{
int i;
for (i = 0; i < n-1; i++) {
if(A[i] >= A[i+1]) {
return 0;
}
}
return 1;
}
When searching for evidence,
ask what evidence is being sought (in the example, that two consecutive values
are out of order) and what values should be checked (in the example, all pairs
(A[0], A[1]), ..., (A[n-2], A[n-1]) ).
8. Example
We
will employ the methodology described in these notes to the following problem,
which involves strings. If s is
a string, then s[k] is the k-th character of s, but
the string is indexed from 0. That is,
the first character of the string is s[0].
The
problem is to read two strings P and T from the keyboard. Generally, P will be shorter than T. The program is then to report whether or not
string P occurs inside string T (without rearranging the characters and without
intervening spaces), and if so, where in string T string P can be found. For example, if P = "hot" and T =
"The hog shot the frog", then the program would report that P occurs
in T starting at the 10-th character.
(Spaces are characters, so the h in shot is the 10-th character.) If P does not occur in T, then the program
should say so.
The
overall program will be captured by procedure main. The description of procedure main is just the preceding
paragraph. Procedure main does the
following.
1. Read P and T from the user.
2. Find out where P occurs in T, if at all.
3. Print the result from step 2.
There are three
subproblems. We will create a procedure
for each one. Since this is somewhat involved, we introduce one approximation:
Find out where "hot" occurs in "The hog shot the
frog". Then we can deal with input
later. So there are only two
subproblems for the approximate problem.
Subproblem
1: find an occurrence of P in T. An initial description is "Find where P occurs in
T, if at all". Detaching that from
its context, we get "Given strings X and Y, find where X
occurs in Y, if at all."
Now we need to make that precise.
There are clearly two in-parameters, X and Y. There is one output, the position where X
occurs in Y. Since that position
will be a positive integer, we are free to use value 0 as an indication that X
does not occur in Y. Since there
is only one output, we will use a function.
Call the function locate.
//
locate(X,Y) returns the position where X occurs in Y, or
//
returns 0 if X does not occur in Y.
//
// in: X The pattern being searched for.
//
// in: Y The string being searched for the
// pattern X.
//
// return-value: The start location of a match where X
// occurs in Y, or 0 if X does
not occur in
// Y. For example, if X = "abc" and Y =
// "ccababcd", then
locate(X,Y) would
// return 5.
int
locate(char* X, char* Y)
Subproblem
2: print the output. Procedure PrintTheOutput(r) will print the output of
the program, where r is the result of locate(P,T). This procedure is quite specific to this problem, so there isn't
much need to detach it from context.
Solution
to procedure main (approximation 1). Procedure
main is now very simple. It is a
sequence of statements.
int
main()
{
char* P;
char* T;
int
r;
P = "hot";
T = "The hog shot the frog";
r = locate(P,T);
PrintTheOutput(r);
return 0;
}
Solution
to subproblem 1: searching for a match.
To determine whether string X
occurs in string Y, we can try each position in Y, asking if X
occurs there. This is an example of a
problem that involves searching for evidence.
If X is "abc" and Y is "ccababcd",
then there are 6 positions to try:
ccababcd
abc
abc
abc
abc
abc
abc
In
general, if X has m characters and Y has n
characters, then there are n-m+1 positions to try.
(In the example, m = 3 and n = 8, so there are 8-3+1 = 6 positions to try.) It
would be easy to explain the method as a loop if we understood how to tell
whether X matches Y at a particular position. The explanation is, "For each k
= 1, 2, ..., n-m+1, check
whether X matches Y at position k. Stop as soon as a match is found, or when
all of the values of k are exhausted." So a subproblem of checking whether X occurs in Y
at a given position is suggested.
Subproblem
3: check for a match. Detaching it
from its context, the procedure or function that checks for a match should take
as parameters two strings A and B, and an integer k, and
tell whether string A occurs in string B starting at position k. Since there is just one output (which will
be either true or false), we will use a function. So subproblem 3 is described as follows.
//
matches(A,B,k) is true if string A occurs in string B
//
starting at position k. Note that the
first position is
//
position 1, not position 0.
// in: A The
pattern
// in: B The
string to find A in
// in: k The
position in B to look for A.
//
// return value: 1 if string A occurs in string B at
// position k, and 0
otherwise. For
// example, if A is
"abc", B is
// "cabcd" and k is
1, then the result
// is 1, since "abc"
occurs in "cabcd"
// starting at position 2.
bool
matches(char* A, char* B, int k)
Now
the solution to subproblem 1 (function locate) is a simple search loop. Variable k holds the current position
being tried. k starts at 1 and
counts until k > n-m+1, or until a match is found, whichever comes
first. A match is found at position k
if matches(X,Y,k) is true. We
use library function strlen to tell the length of a string. After coding in C++, function locate is as
follows.
int
locate(char* X, char* Y)
{
int m = strlen(X);
int n = strlen(Y);
int k;
for(k = 1; k <= n-m+1; k++) {
if(matches(X,Y,k)) return k;
}
return 0;
}
Solution
to subproblem 3: checking for a match. Suppose
that string A has length n.
To determine whether string A occurs at position k in
string B, it suffices to test that A[0] = B[k-1], A[1] = B[k], ..., A[n-1] = B[k+n-2]. (Think of checking for a match at position
1. You must check that A[0] = B[0],
A[1] = B[1], ...) You can
think of this as like a search problem;
you are searching for the first character where A and B
disagree. That is, you are searching
for evidence that A and B do not match at position k, by
looking for characters that do not match.
The loop needs to keep track of
the current position in the A string (variable a_ctr) and the
current position in the B string (variable b_ctr). Initially, a_ctr = 0 and b_ctr = k-1, so that the loop will start by comparing A[0] with B[k]. Each time around the loop, a_ctr and b_ctr
will each be bumped up by 1, so that, for example, the second time around the
loop A[1] will be compared with B[k].
There
should be two ways out of the loop.
Recall that we are using n for the length of string A. If a_ctr >= n, then the entire
string A has been found to match, and the loop should be stopped. If A[a_ctr] is different from B[b_ctr],
then there is a mismatch, so A does not occur inside B at
position k, and the loop should be stopped. So the loop should keep going if a_ctr < n and A[a_ctr] =
B[b_ctr]. After coding in C++, function matches is as follows.
bool
matches(char* A, char* B, int k)
{
int n
= strlen(A);
int a_ctr = 0;
int b_ctr = k-1;
while (a_ctr < n && A[a_ctr] ==
B[b_ctr]) {
a_ctr++;
b_ctr++;
}
return (a_ctr >= n);
}
Solution
to subproblem 2: printing the output. The description of procedure PrintTheOutput is above
void
PrintTheOutput(int result)
{
if (r == 0) cout << "There is no
match";
else cout << "There is a match at
position " << r;
cout << endl;
}
Putting
all of the pieces together yields the following program. The procedures and functions have been
ordered so that each one is defined before it is used.
#include
<iostream.h>
#include
<string.h>
//************************
Matches ********************
//*****************************************************
//
matches(A,B,k) is true if string A occurs in string B
//
starting at position k. Note that the
first position is
//
position 1, not position 0.
// in: A The
pattern
// in: B The
string to find A in
// in: k The
position in B to look for A.
//
// return value: 1 if string A occurs in string B at
// position k, and 0 otherwise.
For
// example, if A is
"abc", B is
// "cabcd" and k is
1, then the result
// is 1, since "abc"
occurs in "cabcd"
// starting at position 2.
//*****************************************************
bool
matches(char* A, char* B, int k)
{
int n
= strlen(A);
int a_ctr = 0;
int b_ctr = k-1;
while (a_ctr < n && A[a_ctr] ==
B[b_ctr]) {
a_ctr++;
b_ctr++;
}
return (a_ctr >= n);
}
//***********************
Locate ************************
//*******************************************************
//
locate(X,Y) returns the position where X occurs in Y, or
//
returns 0 if X does not occur in Y.
//
// in: X The pattern being searched for.
//
// in: Y The string being searched for the
// pattern X.
//
// return-value: The start location of a match where X
// occurs in Y, or 0 if X does
not occur in
// Y. For example, if X = "abc" and Y =
// "ccababcd", then
locate(X,Y) would
// return 5.
//*******************************************************
int
locate(char* X, char *Y)
{
int m = strlen(X);
int n = strlen(Y);
int k;
for(k = 1; k <= n-m+1; k++) {
if(matches(X,Y,k)) return k;
}
return 0;
}
//*******************
PrintTheOutput **********************
//*********************************************************
//
PrintTheOutput(r) prints the output, where r is the
//
result of locate(P,T), P is the pattern being searched
//
for and T is the text being searched.
//*********************************************************
void
PrintTheOutput(int r)
{
if (r == 0) cout << "There is no
match";
else cout << "There is a match at
position " << r;
cout << endl;
}
//**********************
Main ****************************
//********************************************************
int
main()
{
char* P;
char* T;
int r;
P = "hot";
T = "The hog shot the frog";
r = locate(P,T);
PrintTheOutput(r);
return 0;
}
Solution to the full
problem. After testing the first approximation, the next step
is to add reading the input from the keyboard.
Subproblem
4: get the data. An initial description is "read P and
T". This can be detached from its
context by doing two reads, each with an in-parameter that is the prompt, and
an out-parameter that is the string read.
Making this more precise, we get
//
ReadStringWithPrompt(prompt,str) prints prompt and reads
//
a string from the keyboard.
//
The string that was read is put in variable str.
// in: prompt The
prompt
// out: str The
string that was read
//
//
Note: str should be an array where the result will be put.
void
ReadStringWithPrompt(char* prompt, char*
str )
Solution
to subproblem 4. Procedure
ReadStringWithPrompt just prints and reads.
It is as follows. The
description is above.
void readStringWithPrompt(char* prompt, char* str)
{
cout
<< prompt;
cin
>> str;
}
Now
the main program becomes as follows.
There is a modification to create the arrays P and T to hold the input
strings.
int main()
{
char
P[100];
char
T[100];
int r;
ReadStringWithPrompt("What is the pattern string? ", P);
ReadStringWithPrompt("What is the string to search? ", T);
r =
locate(P,T);
PrintTheOutput(r)
return 0;
}
Modification
of the program above to incorporate procedure ReadStringWithPrompt and the
modified procedure main is left to the reader.
A comment should be added at the top of the program indicating what the
program (i.e. main) does.